
Deep Learning
Tags: Deep Learning, IBM
Categories: IBM Machine Learning
Updated:
Learning and Regularization
Tecniques
- Dropout - This is a mechanism in which at each training iteration (batch) we randomly remove a subset of neurons. This prevents a neural network from relying too much on individual pathways, making it more robust. At test time the weight of the neuron is rescaled to reflect the percentage of the time it was active.
- Early stopping - This is another heuristic approach to regularization that refers to choosing some rules to determine if the training should stop.
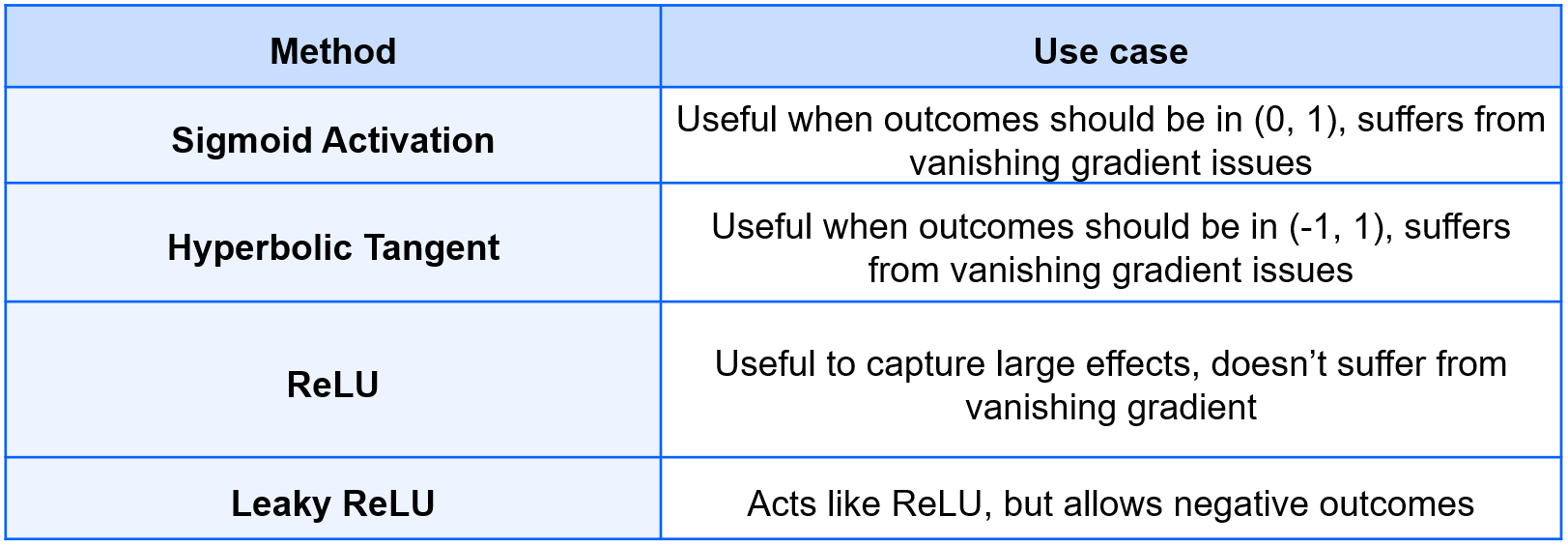
- The “vanishing gradient” problem can be solved using a different activation function: the sigmoid function.
- Every node in a neural network has an activation function.
Acitivation function
Optimization
- Gradient Descent
- Stochastic Gradient Descent: use a single random point at a time.
Optimizers
Standard form of update formul . e.g.)
However, variants!
Momentum
is momentum. Keep running average of the gradient.
nesterov Momentum
Gradient correction!
Adagrad
Update grequentlyudpated weight less, keep running sum of previous updates, divide new upate by factor of previous temrm
RMSProp
Rather than using the sum o
Adam
Both 1st, 2nd order change information and decay both over time
what to use?: RMSprop and Adam is popular
Details of Training model
Minibatch
- Full batch GD
- Stochastic Gradient Descent: steps are less informed,
-
Mini-batch: use a subset of the data at a time. get derivative
of a small set adn take a step in that direction. ->
balance GD and SGD
- if it is small, faster less accurate
- large, slower, more accurate
-
Terminology
- Epoch: single pass through all of the training data.
- in minibatch
Data Shuffling: To avoid any cyclical movement and aid convergecne.
Leave a comment